
智东西
编译 | Glu
编辑 | 李水青
智东西6月27日消息,昨天下午,腾讯云在北京举办了一场面向AI大模型的高性能网络沟通会,在现场首次完整披露了其自研的星脉高性能计算网络。据称,星脉网络具备3.2Tbps业界最高互联带宽,能提升40%的GPU利用率,节省30%~60%的模型训练成本,还让AI大模型通信性能提升10倍。
同时,基于腾讯云新一代算力集群HCC,星脉网络可支持10万卡的超大计算规模。
AI新时代,大模型成为AI领域最火热的话题,各大科技公司纷纷入局,腾讯公司也不例外,继6月19日公布其行业大模型研发进展后,腾讯云副总裁王亚晨、腾讯云数据中心网络总监李翔于今日与智东西等媒体官宣了“星脉网络”实现全新升级,并分享了腾讯云网络研究的发展历程。
王亚晨称:“星脉网络是为大模型而生。它所提供的大带宽、高利用率以及零丢包的高性能网络服务,将助力算力瓶颈的突破,进一步释放AI潜能,全面提升企业大模型的训练效率,在云上加速大模型技术的迭代升级和落地应用。”

▲演讲嘉宾:腾讯云副总裁王亚晨

▲演讲嘉宾:腾讯云数据中心网络总监李翔
一、AI大模型3大网络需求:大带宽、高利用率、无损网络
目前,AI大模型的训练参数已飙升至万亿级别,如此庞大的训练任务无法由单个服务器完成,而需要大量GPU服务器组成算力集群,相互协作完成任务。
这些服务器通过机间网络相连接,不断交换数据。因此,高性能网络具有至关重要的地位,它有利于让算力集群更加快速、准确地完成大规模的训练任务。
大集群不等于大算力,相反,GPU集群规模的扩大还会引发额外的通信开销。因为传统网络架构下,数据传输时会通过多层协议栈,需要反复停下来检查、分拣、打包,导致通信效率低下。
也就是说,网络层级越多,致GPU集群通信性能将越低。现在爆火的生成式AI大模型需要运用千亿、万亿参数规模进行训练,这个训练过程中通信占比最大可达50%,而传统低速网络的带宽无法支撑。
在这个问题的解决上,业界通常会引入RDMA技术(GPU之间直接通信),这是一种高性能、低延迟的网络通信技术,能够允许计算节点之间直接进行数据传输,减少中间环节。
但光靠RDMA技术还远远不够,传统网络协议也将制约GPU集群的运行效率。传统网络协议也很容易导致网络拥塞、高延时和丢包,而仅0.1%的网络丢包就可能导致50%的算力损失,最终造成算力资源的严重浪费。
王亚晨幽默地将传统网络协议喻为“交通管理系统”:“这让所有人都在一条大马路上行走,自然会导致交通堵塞。”
二、3.2Tbps带宽,支持10万卡集群组网
基于以上问题,腾讯云在交换机、通信协议、通信库以及运营系统等软硬件方面进行升级,推出了自研的大模型专属高性能网络“星脉”。
“带宽”决定了能够同时传输的数据,“拓扑”是节点设备间的连接方式,决定了组网规模的大小。在这两项硬指标上,腾讯云称星脉皆达到了业界最高水平。
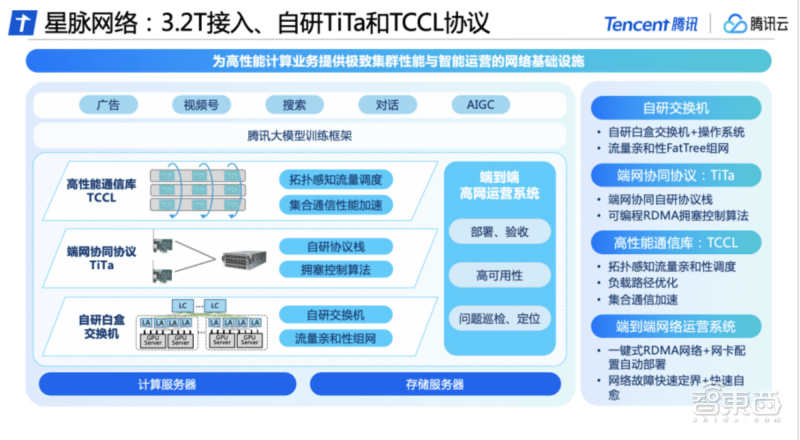
在硬件方面,星脉网络自研白盒交换机,这是一种软硬件解耦的开放网络设备,采用四层解耦体系,包括接入、转发、路由、管控系统;腾讯云还自研了网络操作系统,包括网络OS与网管平台,构建了互联底座,实现自动化部署和配置。
在软件方面,腾讯云自研的TiTa网络协议,能够实时监测并调整网络拥塞,TiTa网络协议能够提升40%的带宽负载,还能提供低延时无损网络,实现高负载下的0丢包,使集群通信效率达90%以上。
王亚晨将其与传统网络协议对比,称:“这是让有不同需求的人走不同的路,就不会导致堵塞了。”
此外,腾讯云还为星脉网络设计了高性能集合通信库TCCL,融入定制化解决方案,使系统实现了微秒级感知网络质量。结合动态调度机制合理分配通信通道,可以避免因网络问题导致的训练中断等问题,让通信时延降低40%。
王亚晨将其比喻为“导航系统”,优化后的集合通信就像有了导航一样,可以快速找到最优路径。
为确保星脉网络的高可用,腾讯云自研端到端全栈网络运营系统。它可以让大模型训练系统的整体部署时间从19天缩减至4.5天,保证基础配置100%准确;通过端网立体化监控与智能定位系统,它可以进行离线故障诊断、在线故障实时告警,让整体故障的排查时间由天级降低至分钟级;此外,它具有秒级的故障自愈能力,端侧会主动发起路径选择,能够极速恢复网络故障。
三、3代演进,17年耕耘,网络硬软件全自研
根据腾讯云官方数据,目前,腾讯云在全球26个地理区域运营70个可用区,同时在70多个国家和地区部署了超过2800个CDN加速节点,全网带宽资源储备超过200T。
而在星脉网络技术升级的背后,是腾讯数据中心网络历经3代技术演进、17年耕耘的成果。
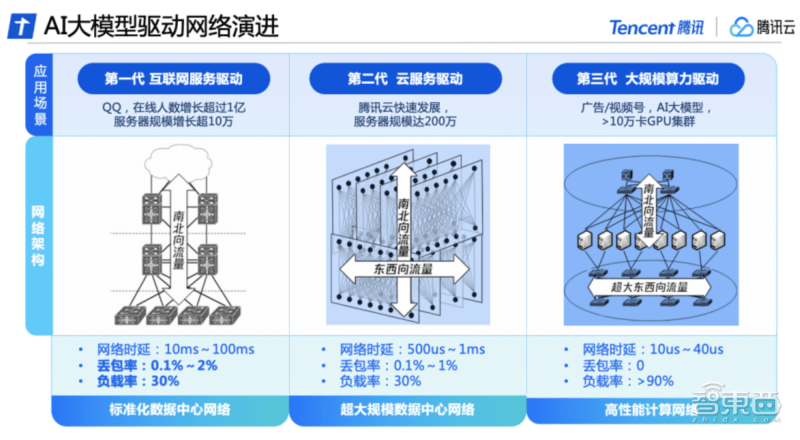
第一代是互联网驱动时期。数据中心网络流量主要由用户访问数据中心服务器的南北向流量构成,网络架构以接入、汇聚、出口为主。这一阶段主要使用了商用网络设备,搭建标准化数据中心网络,支撑QQ在线人数增长超过1亿,服务器规模增长超10万。
第二代是云服务驱动时期。随着大数据和云计算的兴起,服务器之间的东西向流量逐渐增多,云租户对网络产生了虚拟化和隔离的要求。数据中心网络架构逐渐演变为同时承载南北向和东西向流量的云网络架构,腾讯云构建了全自研网络设备与管理系统,打造超大规模数据中心网络,服务器规模近200万台。
第三代是大规模算力驱动时期。随着AI大模型的出现,腾讯云在国内率先推出高性能计算网络,采用东西向、南北向流量的分离架构。构建了独立的超大带宽、符合AI训练流量特征的网络架构,并配合自研软硬件设施,实现整套系统的自主可控,满足超强算力对网络性能的新需求。
日前,腾讯云发布的新一代HCC高性能计算集群,正是基于星脉高性能网络打造,可以实现3.2T超高互联带宽,算力性能较前代提升3倍,为AI大模型训练构筑可靠的高性能网络底座。
结语:面向AI大模型,腾讯星脉网络打助攻
参数达到千亿、万亿级别的AI大模型尤其看重网络性能,它需要大带宽、高利用率、无损的网络来帮助它高效地完成训练任务。以此为契机,腾讯云基于过往17年的网络布局经验与技术成果,研发了助攻AI大模型的星脉网络。星脉网络具备3.2Tbps带宽,可支持10万卡集群组网,能让AI大模型通信性提升10倍。
自OpenAI于去年推出ChatGPT后,各方势力纷纷入局AI大模型,千模大战一触即发。腾讯公司上周了公布其行业大模型的研究进度,腾讯云不“卷”参数,而聚焦到具体产业端,关注AI大模型的落地。此外,他们积极构建高性能网络以助攻AI大模型。此次沟通会中,王亚晨还透露腾讯云正在积极探索下一代高性能网络,致力于构建更强算力的计算集群。